暗号資産の価格分析をするためにOHLCVデータが必要です。Bitgetの暗号資産のヒストリカルデータをAPIで取得する方法をご紹介します。今回はデリバティブの価格を例にしていますが、使用するAPIを変えれば現物の価格のヒストリカルデータも取得可能です。
ローソク足を取得するAPI
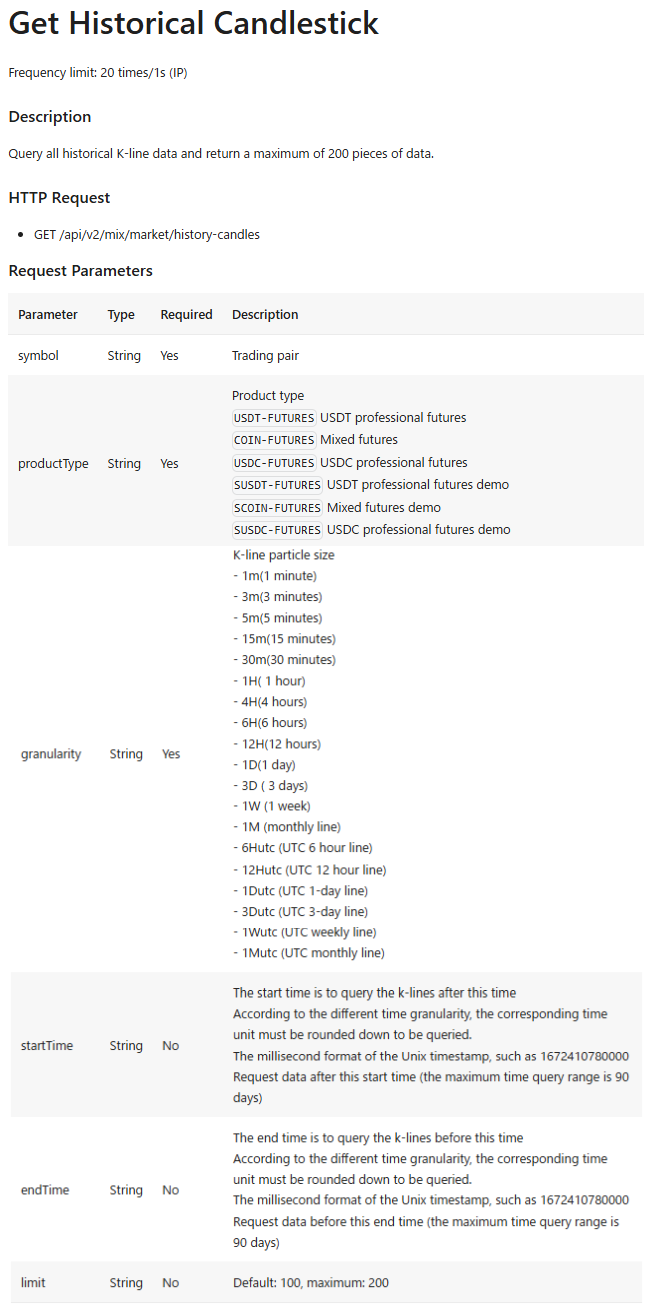
Bitgetのデリバティブ取引のOHLCVデータを取得するAPIには、以下の2つがあります。
- Get Candlestick Data
- Get Historical Candlestick
前者のAPIだと取得できる期間に限りがあるので、この記事では後者のAPIを使います。
出典: Bitget
1分足のOHLCVデータ
BitgetのAPIを使ってOHLCVデータを取得する関数を作成します。通貨ペアはBTCUSDTのデータを取得するコードになっているので、必要に応じて変更してください。
def get_historical_candlestick_data(
candle, # ローソク足の長さ
end_time,
):
endPoint = 'https://api.bitget.com'
path = '/api/v2/mix/market/history-candles'
url = endPoint + path
params = {
'symbol': 'BTCUSDT',
'productType': 'USDT-FUTURES',
'granularity': candle,
'limit': 200,
'endTime': end_time,
}
time.sleep(1)
response = requests.get(url, params)
return response.json()
作成したget_historical_candlestick_data関数を使って、1分足のOHLCVデータを終了時刻を変えて5回取得し、それをつなげてDataFrameにします。(これをあとで使うのでget_ohlcv_1min関数にしておきます。)
def get_ohlcv_1min():
df_1min = pd.DataFrame()
end_time = None
for i in range(5):
res = get_historical_candlestick_data('1m', end_time)
df = pd.DataFrame(
data=res['data'],
columns=[
'timestamp',
'open',
'high',
'low',
'close',
'volume',
'volume_quote',
]
)
# 次回に取得するOHLCVデータの終了時刻を設定する。
# 取得済のOHLCVデータの先頭データが最も過去のデータとなるので、そのタイムスタンプを使用する。
end_time = df.iat[0, df.columns.get_loc('timestamp')]
# タイムスタンプをUNIX時刻からUTC時刻へ変換する。
df['timestamp'] = df['timestamp'].astype('int64').apply(lambda x:datetime.fromtimestamp(x/1000, UTC))
# タイムスタンプをIndexにする。
df = df.set_index('timestamp')
# 不要なカラムは削除する。
df = df.drop(columns=['volume_quote'])
# すべてのカラムを文字列からfloat型に変換する。
df = df.astype(float)
df_1min = pd.concat([df_1min, df], axis='index')
# 重複するデータを削除する。
df_1min = df_1min.drop_duplicates(keep='first')
# Indexのタイムスタンプを昇順でソートする。
df_1min = df_1min.sort_index(ascending=True)
print(df_1min)
return df_1min
get_historical_candlestick_data関数を5回呼び出しているので、200 x 5 = 1,000個のデータが取得できています。重複する行は削除する実装になっていますが、endTimeパラメータは取得するデータに含まれていないようです。
open high low close volume timestamp 2024-12-29 06:51:00+00:00 95127.3 95150.2 95127.0 95149.9 11.206 2024-12-29 06:52:00+00:00 95149.9 95160.3 95149.9 95160.1 32.179 2024-12-29 06:53:00+00:00 95160.1 95188.6 95160.1 95176.3 22.159 2024-12-29 06:54:00+00:00 95176.3 95180.2 95161.8 95161.8 24.674 2024-12-29 06:55:00+00:00 95161.8 95183.9 95161.8 95169.5 37.344 ... ... ... ... ... ... 2024-12-29 23:26:00+00:00 93321.0 93321.1 93268.7 93290.0 52.547 2024-12-29 23:27:00+00:00 93290.0 93368.6 93290.0 93368.6 103.977 2024-12-29 23:28:00+00:00 93368.6 93415.8 93354.7 93398.5 276.099 2024-12-29 23:29:00+00:00 93398.5 93470.0 93398.5 93456.7 226.910 2024-12-29 23:30:00+00:00 93456.7 93576.1 93432.8 93556.4 332.944 [1000 rows x 5 columns]
For文の回数を増やすともっと多くのヒストリカルデータを取得できます。
以上が、1分足のヒストリカルデータを取得するサンプルコードです。
1分足より長いローソク足のOHLCVデータ
1分足から1時間足を作る
1分足のOHLCVデータがあれば、1分足より長いローソク足のOHLCVデータを作ることができます。簡単に言うと、1分足のタイムスタンプをローソク足の長さ単位でFloorして、欲しいローソク足の情報に集約します。
4行目で1分足のOHLCVデータをAPIで取得し、それ以降の処理で1時間足に変換しています。
def make_ohlcv_1hour():
# 1分足のOHLCVデータをAPIで取得する。
df_1min = get_ohlcv_1min()
# 現在のタイムスタンプを1時間単位に丸める。1時間足のタイムスタンプを作成する。
s = pd.Series(df_1min.index.floor('1H'), index=df_1min.index, name='timestamp_1hour')
# 1時間足のタイムスタンプを1分足のOHLCVデータのカラムに追加する。
df_1min = pd.concat([df_1min, s], axis='columns')
# 念の為、1分足のタイムスタンプのIndexを昇順でソートする。
df_1min = df_1min.sort_index(ascending=True)
# 1時間足のタイムスタンプを使い、1時間足のOHLCVデータを作成する。
# 昇順にソートしているので、先頭が始値で、末尾が終値となる。
df_1hour = pd.concat([
df_1min.groupby('timestamp_1hour')['open'].nth(0),
df_1min.groupby('timestamp_1hour')['high'].max(),
df_1min.groupby('timestamp_1hour')['low'].min(),
df_1min.groupby('timestamp_1hour')['close'].nth(-1),
df_1min.groupby('timestamp_1hour')['volume'].sum(),
], axis='columns')
# Indexの名前を"timestamp_1hour"から"timestamp"に変える。
df_1hour = df_1hour.rename_axis('timestamp', axis='index')
# 1時間足のタイムスタンプのIndexを昇順でソートする。
df_1hour = df_1hour.sort_index(ascending=True)
# 先頭と末尾の行は、1時間足分のすべてのデータが含まれていない可能性があるので、削除する。
df_1hour = df_1hour.drop(index=[df_1hour.index[0], df_1hour.index[-1]])
print(df_1hour)
return df_1hour
上のコードの実行結果です。Indexが1時間足になっています。1,000個の1分足データを使って1時間足を作っているので、1,000 / 60分 = 16.666個の1時間足のデータとなります。中途半端になる先頭と末尾の行は削除しています。
open high low close volume timestamp 2024-12-29 07:00:00+00:00 95151.1 95240.0 95043.3 95224.8 1416.586 2024-12-29 08:00:00+00:00 95224.8 95276.0 95038.2 95089.0 1023.285 2024-12-29 09:00:00+00:00 95089.0 95186.9 95012.0 95152.6 1086.027 2024-12-29 10:00:00+00:00 95152.6 95244.2 95078.1 95130.6 2163.602 2024-12-29 11:00:00+00:00 95130.6 95149.2 94968.4 94986.1 1334.595 2024-12-29 12:00:00+00:00 94986.1 95105.5 94859.8 94860.6 2162.208 2024-12-29 13:00:00+00:00 94860.6 94979.0 94709.5 94889.9 2588.518 2024-12-29 14:00:00+00:00 94889.9 95193.7 93959.9 94578.7 12576.411 2024-12-29 15:00:00+00:00 94578.7 94752.8 94354.2 94468.6 3230.382 2024-12-29 16:00:00+00:00 94468.6 94537.9 93553.0 93850.3 12526.503 2024-12-29 17:00:00+00:00 93850.3 94072.0 93740.4 93902.4 4800.310 2024-12-29 18:00:00+00:00 93902.4 93902.4 93555.0 93605.0 5511.860 2024-12-29 19:00:00+00:00 93605.0 93826.2 93333.0 93559.7 3453.177 2024-12-29 20:00:00+00:00 93559.7 93826.9 93305.3 93800.4 2999.085 2024-12-29 21:00:00+00:00 93800.4 93891.1 93100.0 93303.4 3999.038 2024-12-29 22:00:00+00:00 93303.4 93729.5 93000.1 93100.5 6830.548
1時間足をAPIで取得する
1分足のデータから作成した1時間足のOHLCVデータが正しく作成できているか確認するために、APIを使って1時間足のOHLCVデータを取得してみます。
1分足を取得したコードを変更し、1時間足を取得するコードにします。
def get_ohlcv_1hour():
df_1hour = pd.DataFrame()
end_time = None
for i in range(5):
res = get_historical_candlestick_data('1H', end_time)
df = pd.DataFrame(
data=res['data'],
columns=[
'timestamp',
'open',
'high',
'low',
'close',
'volume',
'volume_quote',
]
)
# 次回に取得するOHLCVデータの終了時刻を設定する。
# 取得済のOHLCVデータの先頭データが最も過去のデータとなるので、そのタイムスタンプを使用する。
end_time = df.iat[0, df.columns.get_loc('timestamp')]
# タイムスタンプをUNIX時刻からUTC時刻へ変換する。
df['timestamp'] = df['timestamp'].astype('int64').apply(lambda x:datetime.fromtimestamp(x/1000, UTC))
# タイムスタンプをIndexにする。
df = df.set_index('timestamp')
# 不要なカラムは削除する。
df = df.drop(columns=['volume_quote'])
# すべてのカラムを文字列からfloat型に変換する。
df = df.astype(float)
df_1hour = pd.concat([df_1hour, df], axis='index')
# 重複するデータを削除する。
df_1hour = df_1hour.drop_duplicates(keep='first')
# Indexのタイムスタンプを昇順でソートする。
df_1hour = df_1hour.sort_index(ascending=True)
print(df_1hour)
return df_1hour
1時間足のOHLCVデータをAPIで取得した結果は、以下です。1分足から1時間足を作った結果と合っていることが確認できました。
open high low close volume timestamp 2024-11-18 07:00:00+00:00 92225.1 92415.2 91506.4 91789.0 13459.817 2024-11-18 08:00:00+00:00 91789.0 92235.0 91647.1 91883.5 5574.930 2024-11-18 09:00:00+00:00 91883.5 92333.7 91725.0 91810.1 7287.136 2024-11-18 10:00:00+00:00 91810.1 92120.0 91762.0 91862.3 3473.331 2024-11-18 11:00:00+00:00 91862.3 91915.8 90100.1 90338.8 18962.439 ... ... ... ... ... ... 2024-12-29 18:00:00+00:00 93902.4 93902.4 93555.0 93605.0 5511.860 2024-12-29 19:00:00+00:00 93605.0 93826.2 93333.0 93559.7 3453.177 2024-12-29 20:00:00+00:00 93559.7 93826.9 93305.3 93800.4 2999.085 2024-12-29 21:00:00+00:00 93800.4 93891.1 93100.0 93303.4 3999.038 2024-12-29 22:00:00+00:00 93303.4 93729.5 93000.1 93100.5 6830.548 [1000 rows x 5 columns]
おまけ
ヒストリカルデータ取得にBitgetのアカウントは不要ですが、アカウントをお持ちでなければ、招待コードは以下をお使いください。
- 招待コード: CJQDLF6L
- 招待URL: https://share.bitget.com/u/8JKY6X25
スマホからであれば、以下のQRコードをご利用ください。


